Z-score on a crypto pair is not what you think
The reason it fails on crypto pairs is everything around the math: drifting means, regime-shifting volatility, fake cointegration, missing costs and single-path backtests.
The z-score is correct math. It's just correct math applied to data that breaks the math's assumptions.
When you compute a rolling z-score on the spread between two crypto perpetuals, you are doing the same arithmetic that has been published in cointegration papers since 1987. The arithmetic isn't wrong. What's wrong is that the inputs you are handing it don't satisfy the conditions it needs. The output is a number with the right shape and the wrong meaning.
This is the most common reason traders bounce off pairs trading. They read about it, try the obvious version, get a signal, lose money and conclude that pairs trading doesn’t work on crypto. Pairs trading works on crypto. The obvious version doesn’t. Below are the five reasons why, and what it takes to fix them.
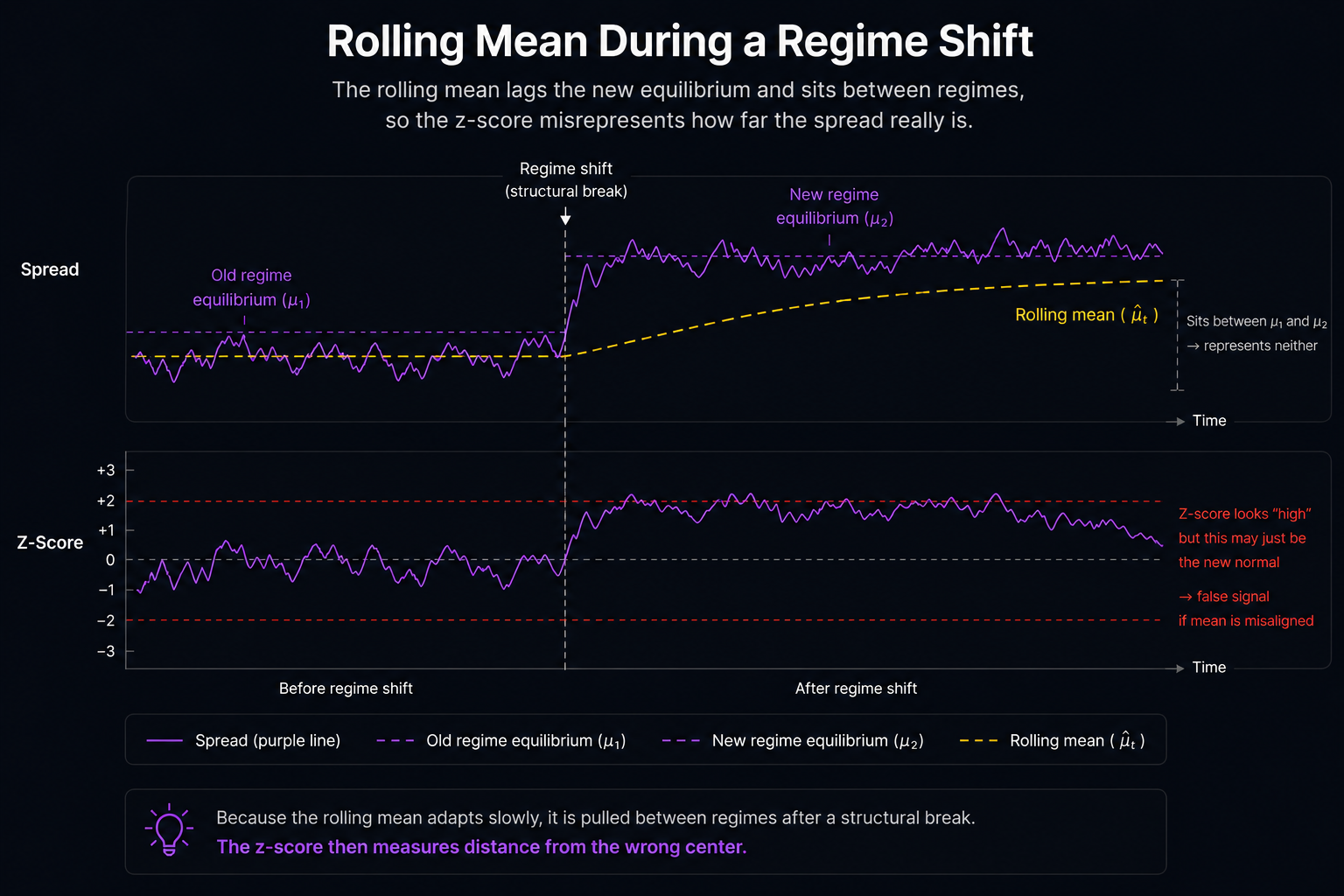
The mean drifts
A z-score is (value − mean) / standard deviation. For the number to mean what the textbook says it means, the mean has to be the value the spread reverts to. On crypto pairs it usually isn't.
Two perps that traded at a 1.0 ratio in March can sit at 0.85 in September because one of them grew faster, the underlying token economics shifted or the relationship genuinely broke. A 20-bar rolling mean across that change is computing the average of two different distributions. Half the window is the old relationship, half is the new. The mean is somewhere in between, representing neither. The z-score against it will tell you the spread is stretched when really the spread has moved to a new equilibrium the window hasn't caught up to yet.
Engle and Granger pinned this down in 1987. A stationary spread requires the right hedge ratio for the current relationship. If the hedge ratio is stale, the spread isn't stationary, and everything downstream stops working.
The standard deviation drifts too
Same problem, denominator edition. The standard deviation in the z-score is supposed to represent the spread's normal volatility. If the spread's volatility regime shifts (one quiet week, one chaotic week, then back) a fixed rolling window mixes the two volatility regimes into a single number that fits neither.
Crypto volatility regimes don't shift gradually. They shift in a single day. A pair that has been calm for three weeks can become turbulent in an afternoon, and a 20-bar standard deviation that includes 19 calm bars and one turbulent bar reports the standard deviation of the calm regime with one outlier-inflated tail. Entry signals computed against it fire constantly during the turbulent period, then disappear two weeks later when the window finally catches up.
Krauss (2017) reviewed the published literature on this. Regime-shift handling is the single largest source of out-of-sample underperformance for naïve z-score implementations.
The pair might not actually be cointegrated
The z-score on a spread only means something if the spread has a real equilibrium to revert to. If the two assets aren't cointegrated, the spread is a random walk and the z-score is the z-score of a random walk. It will mean-revert eventually because all random walks mean-revert eventually, but the timing is undefined and the excursions before reversion can be arbitrarily large. That's not a tradeable signal. It's a way to lose money slowly.
Most pairs picked by visual correlation aren't cointegrated. Visual correlation captures common factors and common shocks. Cointegration captures a stable long-run equilibrium. Two different things. Vidyamurthy (2004) spent half of his book on this. Without a real qualifying test, the rest of the strategy is built on sand.
The backtest doesn't model the costs that matter
A backtest that says your z-score strategy was profitable but doesn't include funding and fees is reporting a fictional number. Perpetual futures fund every eight hours. A position held across the funding stamp pays or receives funding rate times notional. Over a three-day trade, funding can be the single biggest component of P&L, in either direction.
Exchange fees are the next largest piece. The difference between a maker rebate and a taker fee on a typical retail tier is about fourteen basis points of round-trip cost per cycle. On a strategy working on tens of basis points of edge, the fee model is the difference between profitable and not.
Lopez de Prado (2018) put it bluntly. Cost-aware backtesting isn't optional. The cost model has to be at least as detailed as the production cost reality.
A single backtest is one data point
If you ran the strategy on one historical window and the backtest looked good, you have one data point. The historical path that happened is one draw from the distribution of paths that could have happened. The fact that your strategy worked on the one realised path is weak evidence that it will work on the path that follows. Lopez de Prado spends three chapters on this. Walk-forward partitioning, bootstrap and Monte Carlo aren't sophistication. They are the minimum bar.
What a working implementation has to do
The problems above are not problems with the z-score. They are problems with what you're feeding the z-score. To make the math actually work on a crypto pair, the implementation has to:
- Update the hedge ratio continuously, so the mean of the spread is always the right mean.
- Calibrate the normalisation scale to the pair's current volatility regime, so a z-score of 2.5 means roughly the same thing whether the pair is calm or turbulent.
- Filter pairs by structural compatibility before computing anything, so you aren't running the math on a random walk.
- Model funding and fees in the backtest, so the equity curve is the equity curve.
- Resample the backtest, so you have a distribution rather than a single point.
Hedgicore handles all five of those by building the spread differently in the first place. The Hedgicore Engine updates the hedge ratio continuously, calibrates the scale against the current volatility regime, filters by structural compatibility and models funding and fees in the backtest. The Z-score you compute on the Hedgicore spread is doing the textbook math on inputs that satisfy the textbook’s assumptions. A proprietary Hedgicore indicator called Stretch, calibrated specifically for the spread, ships later this year.
The full description is in the methodology paper. Read the methodology →
The point of this post is just that the z-score isn’t broken. The standard way of using it on a crypto pair is, and the fix is in the inputs, not the formula.
References
- Engle, R.F. and Granger, C.W.J. (1987). Co-Integration and Error Correction. Representation, Estimation and Testing. Econometrica 55(2).
- Vidyamurthy, G. (2004). Pairs Trading. Quantitative Methods and Analysis. Wiley.
- Avellaneda, M. and Lee, J.H. (2010). Statistical Arbitrage in the U.S. Equities Market. Quantitative Finance 10(7).
- Krauss, C. (2017). Statistical Arbitrage Pairs Trading Strategies. Review and Outlook. Journal of Economic Surveys 31(2).
- Lopez de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Bonton AI, Hedgicore Research (2026). The Hedgicore Engine. A Methodology for Real-Time Statistical Arbitrage on Crypto Perpetuals. v2.0.
Hedgicore is a real-time pairs analytics platform powered by the Hedgicore Engine. Built by the team at Bonton AI.
Risk disclaimer: Hedgicore is an analytics platform. It does not execute trades or provide financial advice. All trading carries risk of loss.